C#入門編(7)クラス、メソッドによるコードの部品化 ~オブジェクト指向の土台を学ぶ~

C#入門編です。今回は、コードを部品化する演習を行います。
汚いコードを題材として用意して、そのコードを修正して綺麗にしながら、部品化について学んでいきます。
部品化は、ソフトウェアを効率よく開発していくためにとても重要な考え方です。
綺麗なコード/汚いコードとは具体的にどのようなコードなのかを、以下の観点でみていきます。
- 可読性:プログラムの理解しやすさ
- 変更容易性:プログラムの修正・機能追加のしやすさ
- 再利用性:部品としての使いまわしのしやすさ
そして、コードを綺麗にしていくために、
- 「クラス」を用いたデータの部品化
- 「メソッド」を用いた処理の部品化
を行います。

手続き型プログラミングにおけるデータの部品化、処理の部品化の基本を学び、オブジェクト指向へスムーズにステップアップしていけるようにしましょう!
YouTubeの動画でも解説しているので、ぜひ御覧ください。
演習1:汚いコードとは?
今回は以下のようなプログラムを作ってみます。
- ユーザの名前、年齢をコンソールから受け付ける。
- 次に、ユーザの配偶者の名前、年齢もコンソールから受け付ける。
- ユーザとその配偶者それぞれの名前、年齢をHTMLの表形式で出力する。
出力したHTMLが以下のように表示されるのが完成イメージです。
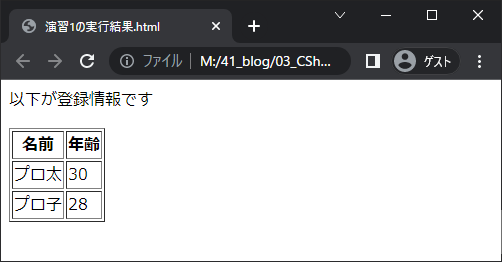
これまで学んできた知識で、プログラムは以下のように書けます。
Console.WriteLine("あなたの情報を入力");
Console.Write("名前を入力:");
string? userName = Console.ReadLine();
Console.Write("年齢を入力:");
int userAge = Convert.ToInt32(Console.ReadLine());
Console.WriteLine("あなたの配偶者の情報を入力");
Console.Write("名前を入力:");
string? partnerName = Console.ReadLine();
Console.Write("年齢を入力:");
int partnerAge = Convert.ToInt32(Console.ReadLine());
Console.WriteLine("<html>");
Console.WriteLine("<body>");
Console.WriteLine($"<p>以下が登録情報です</p>");
Console.WriteLine("<table border=\"1\">");
Console.WriteLine($"<tr><th>名前</th><th>年齢</th></tr>");
Console.WriteLine($"<tr><td>{userName}</td><td>{userAge}</td></tr>");
Console.WriteLine($"<tr><td>{partnerName}</td><td>{partnerAge}</td></tr>");
Console.WriteLine("</table>");
Console.WriteLine("</body>");
Console.WriteLine("</html>");このコードは正しく動きます。
しかし、このコードは汚いコードです。具体的な問題点は、可読性・変更容易性・再利用性が低いことです。
今回の演習では、このコードを例にとり、可読性・変更容易性・再利用性とは何か?そして、なぜ重要か?の説明を行います。
演習のプログラムコードをよく見てみると、似ているけど少し違う冗長な記述が多いことに気づくかと思います。
以下を見てください。
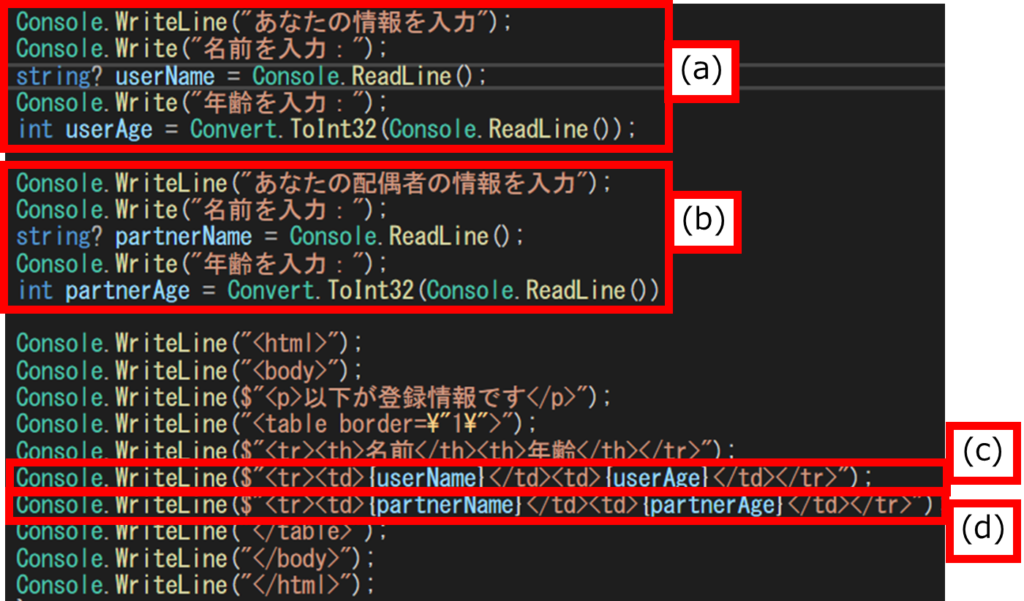
ソースコードの(a)と(b)、(c)と(d)はそれぞれ似ているけど少し違うコードになっていますね。
(a)と(b)では、どちらも名前、年齢をコンソールから入力するコードであり、違いはユーザ(user)と配偶者(partner)の部分のみです。
(c)と(d)は名前・年齢をテーブルの行として出力するコードですが、こちらも違いはユーザと配偶者、どちらの名前/年齢かという部分のみです。
このようなコードには、以下のような問題があります。
- 問題点1(可読性):プログラムが構造化されておらずトップダウンに理解しづらい
- 問題点2(変更容易性):プログラムへ少し変更を加えようとしただけで、修正箇所が広範囲に及ぶ
- 問題点3(再利用性):次に似たような機能を作ろうとしたときに、また同じようなコードを書くことになる
それぞれの問題点を具体的にみていきましょう。
問題点1(可読性):プログラムが構造化されておらずトップダウンに理解しづらい
このプログラムは全く構造化されていないため、内容を理解するためには、全てのコードを1行ずつ読んでいく必要があり、手間がかかります。
これは、章構成がない本やレポートを読むようなものですね。以下を見てください。
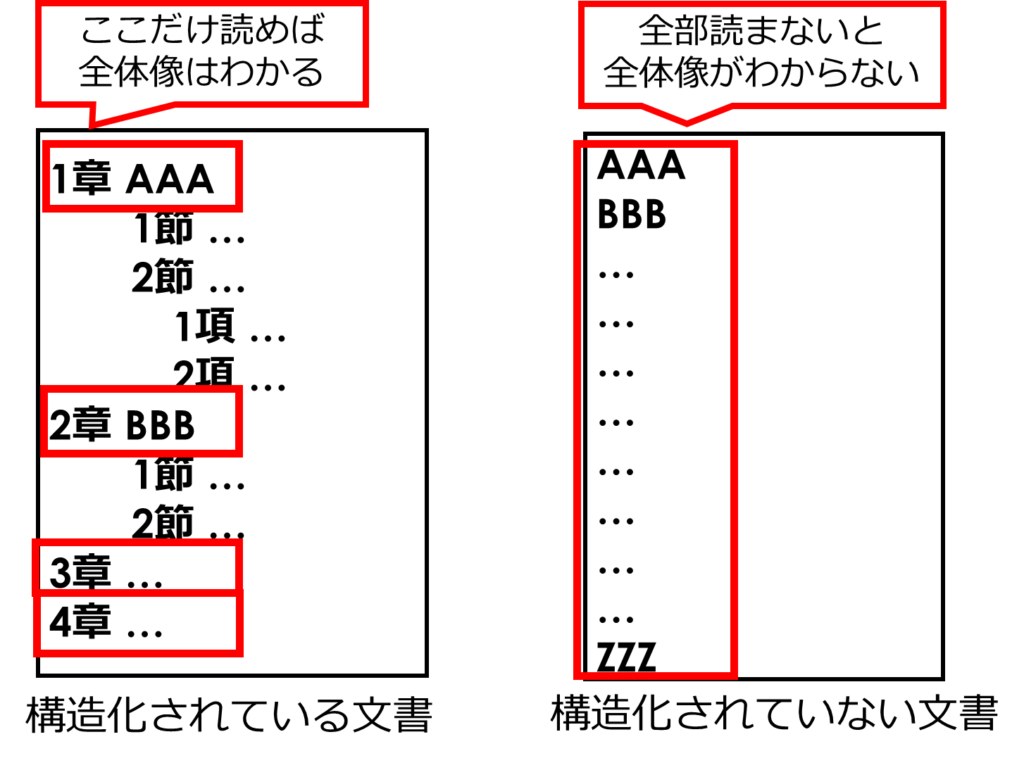
構造化されている文書は、きちんと章立てされているため、まずは章の構成をみれば全体像がつかめますね。
そして、詳細が知りたい章についてはその中身をみていく…というふうにトップダウンに理解していくことが可能です。
一方で、構造化されていない文書はすべて読まないと全体像をつかむことができず、理解に時間がかかります。
プログラムの読みやすさ、理解しやすさを可読性と言います。
演習1プログラムは、まさにこの「構造化されていない文書」と同じであるため、可読性が低いといえます。
問題点2(変更容易性):プログラムへ少し変更を加えようとしただけで、修正箇所が広範囲に及ぶ
例えば、このプログラムで「名前を入力:」とコンソールへ表示する箇所を、「名前を入力してください:」と変更したい場合はどうでしょうか?
ユーザ・配偶者それぞれについて、2箇所も同じような修正が必要になってしまいますね。
名前、年齢に加えて、年収も入力したい場合はどうでしょうか?
これも、ユーザ・配偶者それぞれについて、年収を入力するための似たようなコードを2箇所に書くことになってしまいます。
このように、少しの機能変更についての修正箇所が広範囲に及ぶと、コードを書く作業としても大変です。修正漏れといった誤りも発生しやすくなってしまいますね。
プログラムは正しく動くことに加えて、後から変更・修正しやすいことが大事です。
プログラムの変更・修正のしやすさを「変更容易性」と言います。
プログラムは一度書いて終わりということは少なく、バグ修正や、新たな機能追加のために変更・修正を継続的に行っていきます。
そのため、効率よくプログラムの変更・修正を行えるようにするためには、コードの変更容易性が高いと良いのです。
問題点3(再利用性):次に似たような機能を作ろうとしたときに、また同じようなコードを書くことになる
このプログラムはユーザとその配偶者について扱っていますが、今度は子供についても扱いたくなったらどうでしょうか?
以下のように、コンソールからの入力部分についての似たようなコードがまた増えることになってしまいます。
(一般的に、子供が1人とは限らないですが、いったんそこの話は置いておきます)
Console.WriteLine("あなたの子供の情報を入力");
Console.Write("名前を入力:");
string? childName = Console.ReadLine();
Console.Write("年齢を入力:");
int childAge = Convert.ToInt32(Console.ReadLine());おそらくこのコードは、元のコードをコピー&ペーストしてから変数名を修正する、といった方法で書けると思います。
しかし、この方法では、元のコードについて全て理解した上で必要な部分をきちんと修正する必要があるため、コード規模が大きいと大変です。
加えて、このようなコピー&ペーストしたコードが増えると当然ながら変更容易性も低くなるでしょう。
ある機能を一度作ったらそれを部品化し、その機能の詳細まで把握しなくても簡単に使い回せる(再利用できる)ようにすることで、プログラムを効率よく作れます。
使い回しのしやしさを再利用性と言います。
現状のコードは再利用性も低いということですね。
問題点まとめ
- 可読性が低い:コードが構造化されておらず全て読まないと理解できない
- 変更容易性が低い:少しの変更に伴いあちこち修正が必要となる
- 再利用性が低い:一度作った機能を使いまわしづらい
演習2:データの部品化 ~クラス~
さて、ここからは、演習1プログラムの問題点を段階的に解消していきましょう。
まずは、C#の「クラス」という仕組みを使って、ユーザとユーザの配偶者という似通ったデータを部品化してみます。
演習1プログラムを書き換えたプログラム(演習2プログラム)は以下のようになります。
Person user = new Person(); //★(a1) Personクラスのインスタンスを生成
Console.WriteLine("あなたについての情報を入力");
Console.Write("名前を入力:");
user.name = Console.ReadLine(); //★(b) //Personインスタンスのフィールドへ代入
Console.Write("年齢を入力:");
user.age = Convert.ToInt32(Console.ReadLine());
Person partner = new Person();//★(a2) Personクラスのインスタンスを生成
Console.WriteLine("あなたの配偶者の情報を入力");
Console.Write("名前を入力:");
partner.name = Console.ReadLine();
Console.Write("年齢を入力:");
partner.age = Convert.ToInt32(Console.ReadLine());
Console.WriteLine("<html>");
Console.WriteLine("<body>");
Console.WriteLine($"<p>以下が登録情報です</p>");
Console.WriteLine("<table border=\"1\">");
Console.WriteLine($"<tr><th>名前</th><th>年齢</th></tr>");
//★(c) Personインスタンスのフィールドを参照
Console.WriteLine($"<tr><td>{user.name}</td><td>{user.age}</td></tr>");
Console.WriteLine($"<tr><td>{partner.name}</td><td>{partner.age}</td></tr>");
Console.WriteLine("</table>");
Console.WriteLine("</body>");
Console.WriteLine("</html>");
//★(d) Personクラスの定義
class Person
{
public string? name;
public int age;
}このプログラムでは、Personという新しいデータ型を定義して使っています。
ポイント:クラスとインスタンス
まずコードの一番下に書かれている(d)部分を見てください。ここでは、名前(string型)と年齢(int型)をもつ新たな型としてPerson型を定義しています。
新しい型を定義するときには、「クラス(class)」を使います。そして、nameやageをフィールドと言います。(メンバ、メンバフィールドとも言います)
フィールドは、「型名 フィールド名」で宣言します。
型名の前についているpublicはアクセス修飾子と言います。
アクセス修飾子については、オブジェクト指向におけるカプセル化の説明のときに、あわせて説明します。
ひとまずは、フィールドに誰でもアクセスできるという意味ぐらいに思ってください。
コードの(a1)、(a2)ではnew演算子を使って「new Person()」と記述してPersonクラスの実体化させています。
Person user = new Person(); //★(a1) Personクラスのインスタンスを生成
…
Person partner = new Person();//★(a2) Personクラスのインスタンスを生成クラスで定義した型を実体化したものを「インスタンス」と呼びます。
クラスとインスタンスは、以下のように設計図とその実体という関係になっています。
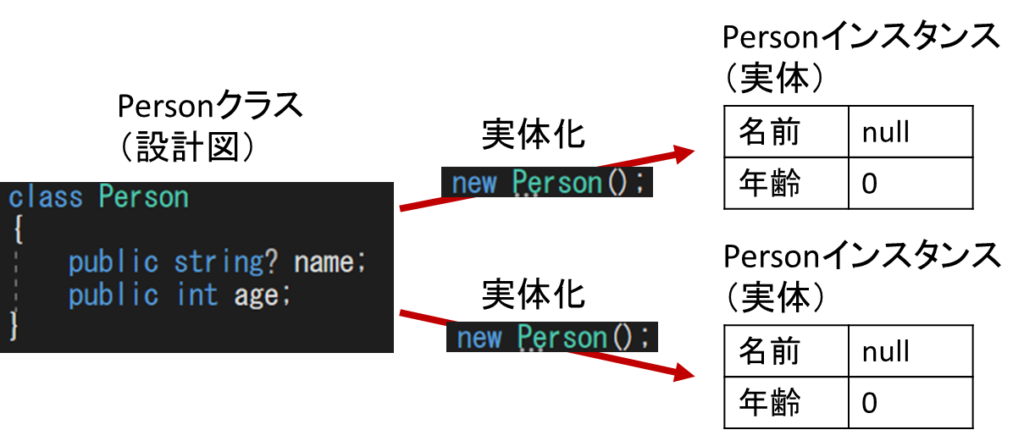
コードの(a1)ではユーザのインスタンス、(a2)では配偶者のインスタンスをそれぞれ生成しています。
それぞれのインスタンスのフィールドへは、メンバアクセス演算子であるドット(.)を用いて代入、参照ができます。
コードの(b)や(c)では、user.nameへ代入、参照を行っています。
user.name = Console.ReadLine(); //★(b) //Personインスタンスのフィールドへ代入
…
//★(c) Personインスタンスのフィールドを参照
Console.WriteLine($"<tr><td>{user.name}</td><td>{user.age}</td></tr>");クラスの定義は、一般的にはクラスごとに別ファイルへ記述するのですが、今回は同じファイル内でクラスを定義しています。
演習で書いてるプログラムは最上位ステートメントといいます。
最上位ステートメントでは、クラス定義は処理を行うコードの後に書く必要があります。
データの部品化により、どのようにコードは綺麗になったか?
今回の演習では、クラスによって人に関連するデータ(名前、年齢)をPerson型として定義して部品化しました。
これによって、プログラムの可読性・変更容易性・再利用性が少しだけ向上しました。
可読性
Person型を導入する前は、人の名前、年齢をそれぞれuserName、uaseAgeとばらばらの変数として宣言していました。
これだと、名前、年齢が関連のある変数であり、それが人の情報であるということがわかりにくかったですね。
Person型を導入したことで、「Person user」が一目で人を表すデータなのだとわかるようになりました。
Person型の詳細が知りたければ、定義を見ればよいわけです。
このようにトップダウンにデータ型を理解できるようになっています。
例えば、もし社員の情報であればPersonよりもEmployeeの方がより良い名前です。
変更容易性
例えば、名前、年齢に加えて年収についても扱いたくなった場合はどうでしょうか?
あちこちのコードを修正しなくても、以下のようにPersonクラスへ新しいフィールドを1つ追加すればよさそうです。
class Person
{
public string? name;
public int age;
public int annualIncome; //★年収を追加
}変更があったときの修正も楽になりましたね。
再利用性
子供についても扱いたくなった場合はどうでしょうか?
この場合は、以下のように新しくPersonインスタンスを生成すればよいでしょう。
Person child = new Person();Personクラスは別のプログラムでも部品として再利用することもできます。
これで、データ型の再利用性も高まりました。
このように、データ部品化によってコードがちょっと綺麗になりました。
しかし、この演習2のプログラムはまだまだ冗長であり、改善の余地がありそうです。
クラスについてはこちらの記事も参考にしてください。
演習3:処理の部品化 ~メソッド~
演習2のコードをさらに改善します。
C#の「メソッド」という仕組みを使って、似たような処理を部品としてまとめます。
演習2プログラムを書き換えたプログラム(演習3プログラム)は以下のようになります。
Person user = ReadPerson("あなた"); //★(a1) メソッド呼び出し
Person partner = ReadPerson("あなたの配偶者"); //★(a2) メソッド呼び出し
Console.WriteLine("<html>");
Console.WriteLine("<body>");
Console.WriteLine($"<p>以下が登録情報です</p>");
Console.WriteLine("<table border=\"1\">");
Console.WriteLine($"<tr><th>名前</th><th>年齢</th></tr>");
WritePerson(user); //★(b1) メソッド呼び出し
WritePerson(partner); //★(b2) メソッド呼び出し
Console.WriteLine("</table>");
Console.WriteLine("</body>");
Console.WriteLine("</html>");
//★(c) 人の情報をコンソールから入力するメソッドを定義
Person ReadPerson(string target)
{
Person user = new Person();
Console.WriteLine($"{target}についての情報を入力");
Console.Write("名前を入力:");
user.name = Console.ReadLine();
Console.Write("年齢を入力:");
user.age = Convert.ToInt32(Console.ReadLine());
return user;
}
//★(d) 人の情報をテーブルの行として出力するメソッドを定義
void WritePerson(Person user)
{
Console.WriteLine($"<tr><td>{user.name}</td><td>{user.age}</td></tr>");
}
class Person
{
public string? name;
public int age;
}このプログラムでは、
- 人の情報を読み込む処理をReadPersonメソッド
- 人の情報をテーブルの行として出力する処理をWritePersonメソッド
として部品化しています。
それでは、これらの具体例をみながらメソッドについて学んでいきましょう。
ポイント1:メソッドの定義
演習プログラム3の(c)の部分にあるReadPersonメソッドの定義を見てみましょう。
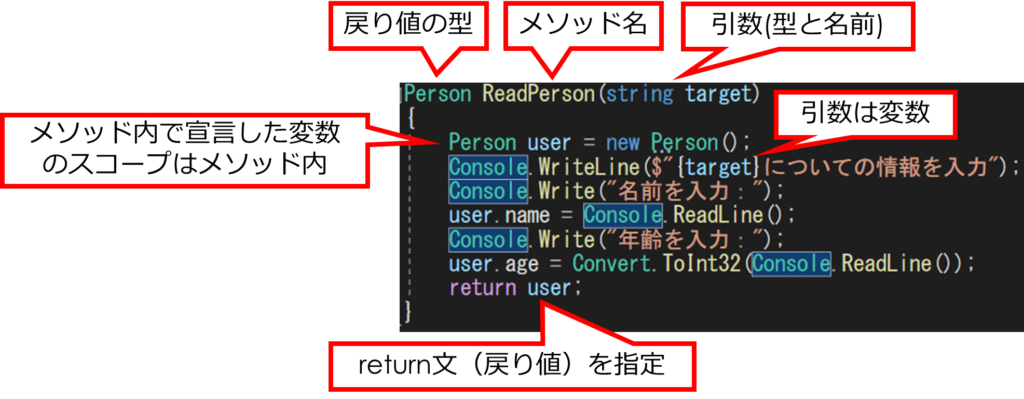
メソッド定義は「メソッドは戻り値の型 メソッド名(引数1, 引数2, …, 引数N){…}」と記述し、ブロック{…}の中に、メソッドの処理内容のステートメントを記述します。
戻り値とは、このメソッドが処理を行った結果として返す値のことです。
このメソッドは次のようなプログラム部品となります。
- 入力(引数):「XXについての情報を入力:」とコンソールへ表示するときのXXの部分
- 出力(戻り値):コンソールから読み込んだデータを基に作成されたPersonインスタンス
メソッド内で、引数は変数として使えますし、もちろん変数を必要に応じて新たに宣言して使うこともできます。
引数や、メソッド内で宣言した変数のスコープはメソッド内に閉じたものとなります。
「return 式;」というステートメントを記述すると、その式の値がメソッドの戻り値となり、メソッド呼び出しが終了し、メソッド呼び出し元へと制御が移ります。
次に、(d)の部分にあるWritePersonメソッドの定義を見てください。
//★(d) 人の情報をテーブルの行として出力するメソッドを定義
void WritePerson(Person user)
{
Console.WriteLine($"<tr><td>{user.name}</td><td>{user.age}</td></tr>");
}このメソッドは、Personの情報をテーブルの行としてコンソールへ出力するメソッドです。
このメソッドには戻り値がないですね。そのような場合、戻り値の型はvoid(戻り値なし)を指定します。
ポイント2:メソッドの呼び出し
(c)で定義したReadPersonメソッドは、(a1),(a2)でそれぞれ呼び出されています。(a1)をみてみましょう。
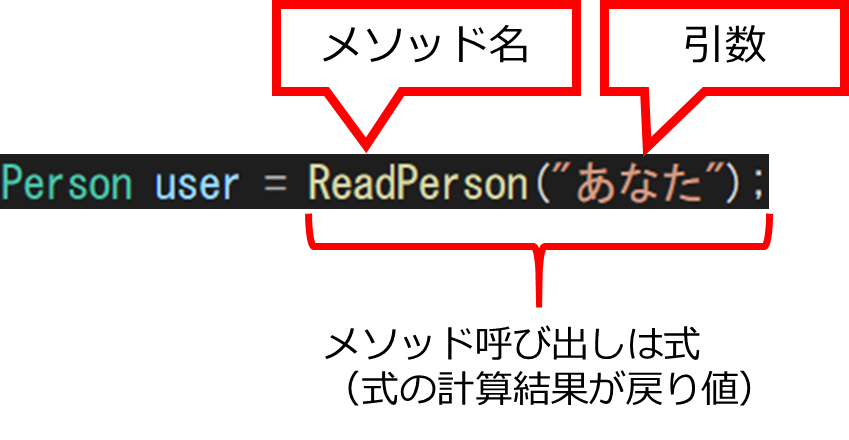
メソッドの呼び出しは、メソッド名(引数1,…,引数N)と記述します。
引数には式を記述できます。そして、メソッド呼び出し自体も式であり、その計算結果が戻り値です。
(a1)、(a2)で部品化したReadPersonをそれぞれ呼び出しています。
Person user = ReadPerson("あなた"); //★(a1) メソッド呼び出し
Person partner = ReadPerson("あなたの配偶者"); //★(a2) メソッド呼び出し同様に、(b1),(b2)では、(d)で定義したWritePersonメソッドをそれぞれ呼び出しています。
WritePerson(user); //★(b1) メソッド呼び出し
WritePerson(partner); //★(b2) メソッド呼び出し処理の共通部分をくくりだし、異なる振る舞いをさせたい部分を引数にすることで、似たような機能をメソッドとしてまとめているわけです。
これで、だいぶコードの冗長さが減りましたね。
処理の部品化により、どのようにコードは綺麗になったか?
演習3プログラムの主な部分を再掲します。
Person user = ReadPerson("あなた"); //★(a1) メソッド呼び出し
Person partner = ReadPerson("あなたの配偶者"); //★(a2) メソッド呼び出し
Console.WriteLine("<html>");
…
WritePerson(user); //★(b1) メソッド呼び出し
WritePerson(partner); //★(b2) メソッド呼び出し
…
Console.WriteLine("</html>");
//★(c) 人の情報をコンソールから入力するメソッドを定義
Person ReadPerson(string target)
…
//★(d) 人の情報をテーブルの行として出力するメソッドを定義
void WritePerson(Person user)
…
class Person
…可読性
人の情報をコンソールから読み込む処理、テーブルの行としてコンソールへ出力する処理が、それぞれReadPersonメソッド、WritePersonメソッドの呼び出しになりました。
例えばReadPersonを見れば、「あ、これはPersonの情報を読み込んでいるな」とすぐにわかります。詳細が知りたければReadPersonの定義を見るとわかりますね。
これで、処理についてもトップダウンに理解ができるようになり、可読性が向上しました。
変更容易性
共通的な処理は、ReadPerson、WritePersonメソッドという共通部品としてまとまっています。
そのため、処理内容を変更したい場合には、プログラム内のあちこちを修正せずとも、ReadPerson、WritePersonを修正すればよいです。
これで、プログラムの修正が容易になり、変更容易性が高くなりました。
再利用性
例えば、ReadPersonというメソッドは次のような入出力でした。(再掲します)
- 入力(引数):「XXについての情報を入力:」とコンソールへ表示するときのXXの部分
- 出力(戻り値):コンソールから読み込んだデータを基に作成されたPersonインスタンス
この入力と出力さえわかれば、詳細な中身の処理を知らなくても、ReadPersonメソッドを利用できます。
これにより、部品として取り回しがしやすくなり、コードの再利用性が高くなっています。
例えば、
- 前半の人の情報を読み込む処理をReadPersonsメソッド
- 後半のHTMLを出力する処理をWriteHTMLメソッド
というふうにまとめると、より理解しやすいコードになりそうです。
メソッドについてはこちらの記事なども参考にしてください。
講義1:部品化はなぜ重要か?
演習を通して、部品化により可読性・変更容易性・再利用性が高まることはわかってもらえたかと思います。
プログラミングにおいて、部品化は以下の観点からも重要です。
- (1)既存部品をいかにうまく使うかがキモとなる
- (2)部品化の手段として様々な言語機能がある
これらについてそれぞれ説明します。
(1)既存部品をいかにうまく使うかがキモとなる
誰もが共通に使う部品はプログラミング言語で標準的に提供されていて、標準ライブラリなどと呼ばれます。
実は、これまでの例で何度もでてきていたConsole.WriteLineというコンソール画面への出力を行う命令はC#の標準ライブラリとして提供されるメソッドです。
標準ライブラリ以外にも、便利な部品が世の中に多く存在しています。
今ですとオープンソースソフトウェア(OSS)のライブラリとして多く存在していますね。
これは、標準ライブラリに対して、第三者ライブラリ・サードパーティライブラリなどと呼ばれます。
実用的なアプリケーション開発では、既存部品をいかにうまく使うかがキモになります。
だいたいのアプリケーション開発ではこのようなイメージですね。

もう既存部品がほとんどで、自分が作る部分はわずか、という感じです。
なにか実用的なアプリケーションを開発しようと思ったら、プログラミング言語自体の学習に加えて「作りたいものに応じた既存部品の使い方」の学習も必要です。
巨大な既存部品の例としては、
- ゲーム開発のためのUnity
- Webアプリケーション開発のためのASP.NET
などがあげられます。
(2)部品化の手段として様々な言語機能がある
C#を学んでいると、オブジェクト指向、デリゲート、ジェネリクスなどいろいろな概念、仕組みがでてきますね。
最初は、「なかなか難しくて理解しにくい、そもそも何の役に立つのだろうか?」などと思うことがあるかもしれません。
しかし、これらの本質をつきつめていくと、可読性・変更容易性・再利用性などを高めるために用意された「部品化を行うための手段」の1つであることがわかります。
そのような点を意識すると、新しい概念・仕組みも少し学びやすくなるかと思います。
まとめ
今回は、プログラミングにおいて重要な考え方である部品化について説明しました。
具体的には、データの部品化を行うクラス、処理の部品化を行うメソッドの基本的な使い方を紹介しました。
これで、可読性・変更容易性・再利用性の高いコードが書けるようになりました。
今回、部品化の基本を学ぶということで、データの部品化、処理の部品化をそれぞれ別々に行いました。
オブジェクト指向では、データと処理を1つにまとめて部品化します。
今日学んだことを土台として、次回から本格的にオブジェクト指向について学んでいきます。






