C#入門編(8)オブジェクト指向とは?「カプセル化」 ~部品をブラックボックスとして使えるようにする~

C#入門編です。前回の演習では、手続き型プログラミングの考え方で、データの部品化と処理の部品化を個別に行いました。

オブジェクト指向の考え方では、データとそれに対する処理をひとまとまりの「オブジェクト」として部品化することで、再利用性と可読性を向上させます。
そして、オブジェクト群が連携して動作するようプログラミングを行い、システムを作ります。
それぞれのオブジェクトは、必要な機能のみ外部に公開されたブラックボックスとして使えるよう設計します。これをカプセル化といいます。
カプセル化によって、オブジェクトの内部構造や実装の詳細を隠蔽します。これにより、オブジェクトの利用者はオブジェクトの機能のみ理解すればよく、安全に使うことができます。
今回は具体的なコードを用いて演習を行いながら、以下について学んでいきましょう。
- オブジェクト指向の基本的な考え方
- カプセル化とは何か?何が嬉しいのか?
- カプセル化を実現するための機能

- カプセル化
- 継承
- 多態性(ポリモーフィズム)
今回は、「カプセル化」が話の中心となります。
YouTubeの動画でも解説しているので、ぜひ御覧ください。
演習1:カプセル化 ~部品のブラックボックス化~
演習1コード
前回と同様に以下のようなプログラムを作ります。
- ユーザの名前、年齢をコンソールから受け付ける。
- 次に、ユーザの配偶者の名前、年齢もコンソールから受け付ける。
- ユーザとその配偶者それぞれの名前、年齢をHTMLの表形式で出力する。
今回、人の情報の管理や入出力の操作について、Pesronクラスという1つの部品にまとめます。
そして、Personクラスの利用者が、詳細にどのようなデータ(名前、年齢など)をもつかを知らなくても、
- コンソールから人の情報を読み込ませる
- HTMLのテーブルの行として情報を出力する
という操作を行えるような部品にしてみましょう。
前回の演習で作った、データと処理を個別に部品化しているコード(少しだけメソッド名、変数名など修正しています)は以下のようになります。
// ■処理のコード■
Person user = ReadPersonFromConsole("あなた");
Person partner = ReadPersonFromConsole("あなたの配偶者");
Console.WriteLine("<html>");
Console.WriteLine("<body>");
Console.WriteLine($"<p>以下が登録情報です</p>");
Console.WriteLine("<table border=\"1\">");
Console.WriteLine("<tr><th>名前</th><th>年齢</th></tr>");
WritePersonAsTableRow(user);
WritePersonAsTableRow(partner);
Console.WriteLine("</table>");
Console.WriteLine("</body>");
Console.WriteLine("</html>");
// ■ここからは、メソッドの定義■
Person ReadPersonFromConsole(string target)
{
Person user = new Person();
Console.WriteLine($"{target}についての情報を入力");
Console.Write("名前を入力:");
user.name = Console.ReadLine();
Console.Write("年齢を入力:");
user.age = Convert.ToInt32(Console.ReadLine());
return user;
}
void WritePersonAsTableRow(Person person)
{
Console.WriteLine($"<tr><td>{person.name}</td><td>{person.age}</td></tr>");
}
// ■ここからは、クラスの定義■
class Person
{
public string? name;
public int age;
}このコードでは、以下のようにデータと処理を個別に部品化しています。
- 名前、年齢の情報をもつ人を表すデータをPersonクラスとして定義
- 人の情報を読み込む処理をReadPersonFromConsole、HTMLのテーブル行として出力する処理をWritePersonAsTableRowメソッドとして定義
オブジェクト指向の考え方では、データとそれに対する処理をひとまとまりの「オブジェクト」として部品化します。
書き換えたコード(演習1プログラム)が以下になります。元のコードと違うのは★の部分です。
// ■処理のコード■
Person user = new Person();
user.ReadFromConsole("あなた"); //★(a1)オブジェクトを操作
Person partner = new Person();
partner.ReadFromConsole("あなたの配偶者"); //★(a2)オブジェクトを操作
Console.WriteLine("<html>");
Console.WriteLine("<body>");
Console.WriteLine($"<p>以下が登録情報です</p>");
Console.WriteLine("<table border=\"1\">");
Console.WriteLine("<tr><th>名前</th><th>年齢</th></tr>");
user.WriteAsTableRow(); //★(b1)オブジェクトを操作
partner.WriteAsTableRow(); //★(b2)オブジェクトを操作
Console.WriteLine("</table>");
Console.WriteLine("</body>");
Console.WriteLine("</html>");
// ■ここからは、クラスの定義■
class Person
{
private string? name; //★(c1)外部へは非公開
private int age;//★(c2)外部へは非公開
//★(d1)外部公開する操作(メソッド)を定義
public void ReadFromConsole(string target)
{
Console.WriteLine($"{target}についての情報を入力");
Console.Write("名前を入力:");
name = Console.ReadLine();
Console.Write("年齢を入力:");
age = Convert.ToInt32(Console.ReadLine());
}
//★(d2)外部公開する操作(メソッド)を定義
public void WriteAsTableRow()
{
Console.WriteLine($"<tr><td>{name}</td><td>{age}</td></tr>");
}
}それでは、具体的にポイントをみていきましょう。
ポイント1:オブジェクト指向の考え方
オブジェクト指向では、「オブジェクト」という部品群が連携し、システム全体が動作するというふうに考えてプログラミングを行います。
オブジェクトとは、データとそれに対する操作のセットです。
C#におけるオブジェクトは、クラスのインスタンスと考えてもらってよいです。
演習1のプログラムにおけるPersonクラスを見てください。
class Person
{
private string? name; //★(c1)外部へは非公開
private int age;//★(c2)外部へは非公開
//★(d1)外部公開する操作(メソッド)を定義
public void ReadFromConsole(string target)
{
…
}
//★(d2)外部公開する操作(メソッド)を定義
public void WriteAsTableRow()
{
…
}
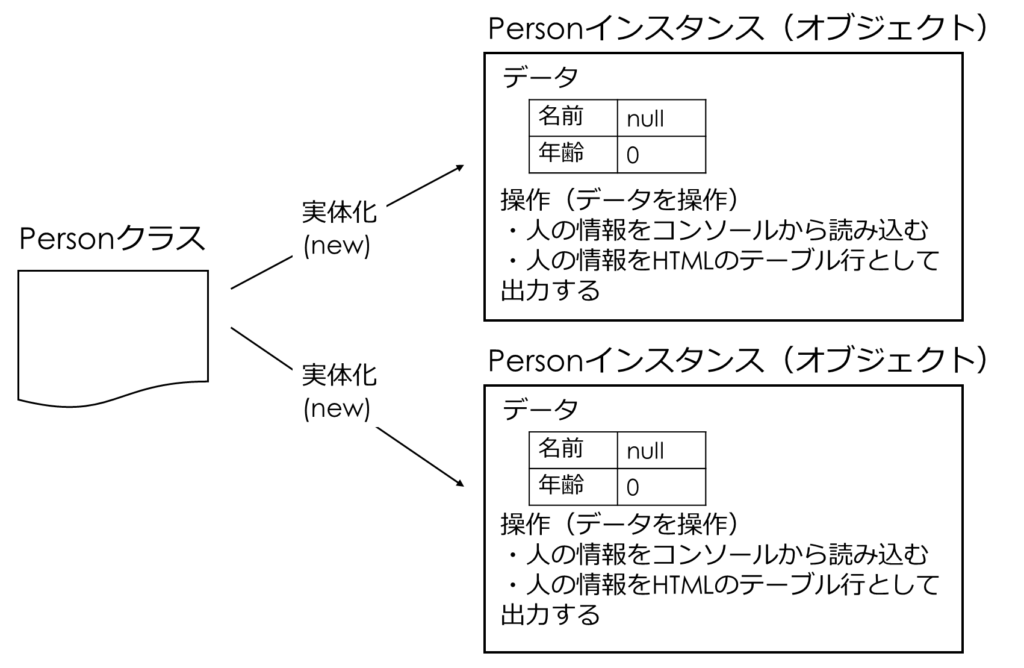
}Personクラスは、以下のようなインスタンス(オブジェクト)の設計図といえます。
- 名前と年齢をデータとして持つ (コードの(c1)、(c2)部分)
- 人の情報をコンソールから読み込、人の情報をHTMLのテーブル行として出力するという操作を行うことができる(コードの(d1)、(d2)部分)
Personのクラス、インスタンス(オブジェクト)、データ、操作のイメージは以下のようになります。
元のプログラムでは、人の「データ」と、人のデータに対する操作を行う「処理」は別々でしたね。
オブジェクト指向では、データとそれに対する操作をPersonクラスとして1つにまとめて扱います。
このように1つにまとめることで何が嬉しくなるのかについては、次のポイントで説明します。
ポイント2:カプセル化
オブジェクト指向では、部品をブラックボックス化し、それによりその部品の再利用性を高めています。
部品を使う側から見て、ブラックボックスとして中身の詳細を知らずとも使える、という意味です。
Personクラスを見ると、
- name、ageというフィールドはprivate
- ReadFromConsole、WriteAsTableRowにはpublic
というアクセス修飾子がついていますね。
private string? name; //★(c1)外部へは非公開
private int age;//★(c2)外部へは非公開
//★(d1)外部公開する操作(メソッド)を定義
public void ReadFromConsole(string target) …
//★(d2)外部公開する操作(メソッド)を定義
public void WriteAsTableRow()…これらはそれぞれ以下の意味になります。
- private:定義された型(クラス)内からのみアクセスできる
- public:どこからでもアクセスできる
ReadFromConsole、WriteAsTableRowという操作のみ公開されていて、name、ageといった部分は非公開です。
このようにすることで、この部品を使う人へ必要な操作のみを公開し、内部の詳細なつくりについては非公開にしているのです(非公開にすることを隠蔽するともいいます)。
こうすることで、この部品を使う人は必要な操作のみ知ればよく、内部の詳細なつくりを気にする必要はありません。
加えて、想定外の使われ方をされることも防げるのです。
以下のようなイメージです。
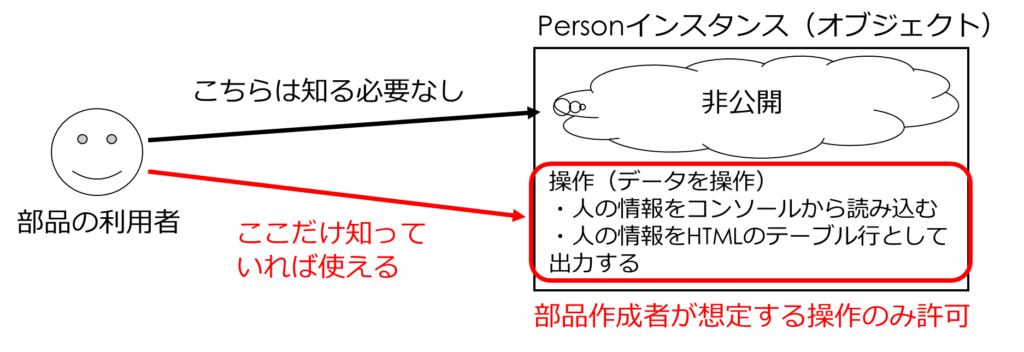
このように、部品をブラックボックス化し、必要な操作のみ外部へ公開するという考え方を「カプセル化」といいます。
カプセル化により、部品の再利用しやすくなります。
カプセル化されているものは、実は我々の身の回りにもあります。
例えば、エアコンを操作するリモコンは、以下のようにカプセル化されていると考えられます。
- 外部へ公開:暖房、冷房の切り替え、温度調整といった操作など
- 非公開:エアコン本体との通信、内部データ、電源の管理など
リモコンを操作する人は、通信など内部の詳細な仕組みを知らなくても使えます。誤って内部データを不正な値に書き換えて故障させてしまうといったこともありません。
Personクラスもリモコンも、同じカプセル化の考え方で設計しているのです。
フィールドは外部から勝手に値を変えられると不都合な事が多く、またカプセル化の基本的な考え方として、データは隠蔽して操作のみ公開するというものがあるためです。
ただ、カプセル化の本質は「データは必ず隠蔽しよう」ではなく、「必要最低限のものだけ外部へ公開して残りは隠蔽する」という点です。
アクセス修飾子の種類については、この記事も参考にしてください。
よく使うアクセス修飾子は、private、public、あとはprotected、internalあたりです。
protectedについては、「継承」の話をするときに併せて説明します。
ポイント3:データに対する操作
データに対する操作を行うのがメソッドです。メソッドの定義方法と呼び出し方をそれぞれ説明します。
メソッド定義
クラスにおけるメソッドの定義方法についてみてきましょう。
基本的には、前回説明したメソッドの定義方法と大きくは変わらないのですが、以下の点が少し異なります。
- アクセス修飾子をつける
- メソッド内でフィールドを参照できる
1点目はポイント2で説明しました。2点目について、(d1)のReadFromConsoleを例にとり説明します。
//★(d1)外部公開する操作(メソッド)を定義
public void ReadFromConsole(string target)
{
…
name = Console.ReadLine();
…
age = Convert.ToInt32(Console.ReadLine());
}メソッド内ではフィールドを参照できます。ここでは、name、ageフィールドへ代入を行っていますね。
アクセス権がprivateとなっているフィールドについても、そのフィールドが宣言されたクラス内で定義されているメソッドからは参照可能です。
メソッド呼び出し
次に定義したメソッドの呼び出しについて、コードの(a1)、(a2)を例にとって見てみましょう。
Person user = new Person();
user.ReadFromConsole("あなた"); //★(a1)オブジェクトを操作
Person partner = new Person();
partner.ReadFromConsole("あなたの配偶者"); //★(a2)オブジェクトを操作インスタンスのフィールド参照と同様に、メンバアクセス演算子(.)を用いて、user.ReadFromConsoleと記述することで、対象インスタンス(この場合だとuser)に対してメソッドを呼び出します。
userに対してメソッド呼び出しを行うとuserインスタンスのデータ(フィールド)が、partnerに対して呼び出せばpartnerインスタンスのデータ(フィールド)が、それぞれメソッド内で操作されます。
以下の(b1)、(b2)の部分も同様です。
user.WriteAsTableRow(); //★(b1)オブジェクトを操作
partner.WriteAsTableRow(); //★(b2)オブジェクトを操作これで、Personクラスの利用者は、Personインスタンスがどのようなデータを保持しているかを意識せず、コンソールからの入力、HTMLコードとしての出力を行えるようになりました。
PersonクラスのReadFromConsoleや、WriteAsTableRowメソッドのように、各インスタンスのデータを参照・操作するメソッドをインスタンスメソッドと呼びます。
また、name、ageのようにインスタンスごとに存在するフィールドをインスタンスフィールドと呼びます。
これらをまとめてインスタンスメンバと呼びます。
インスタンスごとではなく、クラスで唯一存在するクラスフィールド、インスタンスフィールドの参照・操作を伴わないクラスメソッドも定義可能です。
これらをクラスメンバと呼びます。
クラスメンバについては、次の演習で説明します。
演習2:ブラックボックス化をさらに進めるためのコード改善 ~インスタンスメンバとクラスメンバ~
演習1で、オブジェクト指向の基本的な考え方や、カプセル化を行うことで再利用性が上がる点についてはなんとなくわかってきたでしょうか。
カプセル化では、部品をブラックボックスとして使える点が重要という話をしました。
ところが実は、演習1のコードはブラックボックス化できていない部分があります。
演習2では、Personクラスという部品のブラックボックス化を更に進めましょう。進める中で、クラスメンバの使い方についても説明します。
演習1コードの問題点
テーブルの行としてPersonの情報を出力するコードを見てください。
Console.WriteLine("<tr><th>名前</th><th>年齢</th></tr>");
user.WriteAsTableRow(); //★(b1)オブジェクトを操作
partner.WriteAsTableRow(); //★(b2)オブジェクトを操作
Console.WriteLine("</table>");Personクラスは、名前、年齢という内部データは隠蔽するよう設計しました。
しかし、WriteAsTableRowで人の情報を出力する前に、テーブルヘッダ「<tr><th>名前</th><th>年齢</th></tr>」を出力しています。
Personインスタンスの利用者が、「Personは名前・年齢という情報を持ち、この順序で出力が行われる」ということを知る必要がありますね。
Personという部品をうまくブラックボックス化できていないのです。
例えば、Personへ「年収」という新しいフィールドが追加された場合、Personクラスの利用者はそれを把握し、自分のコードを書き換える必要があります。
コードの改善(演習2コード)
問題を改善するための1例としては、テーブルヘッダを出力する機能も、Personクラスに持たせるのがよいでしょう。
例えば、以下のようなWriteTableHeaderというインスタンスメソッドをPersonクラスに追加しましょう。
class Person{
…
public void WriteTableHeader()
{
Console.WriteLine("<tr><th>名前</th><th>年齢</th></tr>");
}
}WriteTableHeaderメソッドを使うと、テーブルを出力する部分のコードを次のように書き換えられます。
Console.WriteLine("<table border=\"1\">");
user.WriteTableHeader();
user.WriteAsTableRow();
partner.WriteAsTableRow();
Console.WriteLine("</table>");これで、Personクラス利用者はどのようなデータを持つか意識する必要はなくなり、完全にブラックボックスな部品として使えます。
Personクラスへ「年収」フィールドが追加されたとしても、Personクラス側が適切に修正されていれば、利用者は自分のコードを書き換えなくてすみます。
ところで、WriteTableHeaderメソッドの中身の処理をよく見ると、インスタンスフィールドを参照していないですね。
クラスに関連する操作・処理ではあるけども、インスタンスフィールドを参照する必要がないメソッドはクラスメソッドとして定義できます。
クラスメソッドは以下のようにstaticをつけて定義します。
// クラスメソッドの定義
public static void WriteTableHeader()
{
Console.WriteLine("<tr><th>名前</th><th>年齢</th></tr>");
}クラスメソッドはインスタンスメソッドと異なり、特定のインスタンスに結びついているわけではなく、クラス自体に結びついています。
そのため、クラスメソッド内では、クラスメンバのみ参照可能で、インスタンスメンバは参照できません。
クラスメソッド呼び出しは、以下のようにクラス名に対して、メンバアクセス演算子(.)を用いて行います。
Person.WriteTableHeader(); //クラスメソッド呼び出し
user.WriteAsTableRow(); //インスタンスメソッド呼び出し
partner.WriteAsTableRow(); //インスタンスメソッド呼び出しクラスフィールドを定義するときも、同様にstaticをつければよいです。
そのクラス(型)に関連はするけど、個別のインスタンスに結びつくわけではないメンバ(フィールドやメソッド)は、クラスメンバとして定義できるわけですね。
演習3:クラスには1つの責任を持たせる ~コンストラクタ、プロパティ~
演習2コードの問題点
演習2を通して、Personクラスのカプセル化を進めてきましたが、まだ少し問題点があります。
オブジェクト指向のクラス設計では、単一責任の原則というものがあります。
1つのクラスには1つの責任(1つの役割)をもった部品として設計すると以下の利点があるのです。
- 汎用性が高くなり、再利用性が向上する
- 何か修正があったときに、修正の影響範囲が小さくなる
演習2のPersonクラスは、以下のようにいくつかの異なる責任を持っています。単一責任の原則からすると、もう少しクラスを分割したほうが良いのです。
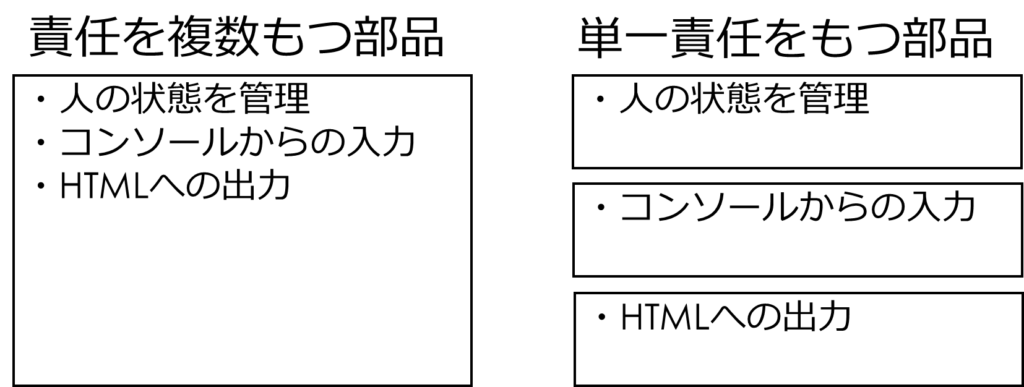
1つの責任のみ持つPersonクラス(演習3コード)
演習3では、Personクラスを以下のような機能も持たせた、「人の状態の管理」をするという責任のみをもつ部品にしてみましょう。
- 名前、年齢を(コンソール入力ではなく)プログラムコード中で具体値を指定して、インスタンスを生成可能にする。
- インスタンスの名前の値を外部から読み取り可能にする。ただし、外部からの書き換えは不可とする。
- インスタンスの年齢の値を外部から読み取り/書き換え可能にする。年齢の値を0未満の値で書き換えることができないようにする。
このような機能を持たせたPersonクラスのコードは以下のようになります。
class Person
{
private string? name;
private int age;
//★(a) コンストラクタ
public Person(string? name, int age)
{
this.name = name;
this.age = age;
}
//★(b1) プロパティ (読み取りのみ)
public string? Name
{
get { return name; }
}
//★(b2) プロパティ (読み取り/書き込み両方)
public int Age
{
get { return age; }
set {
if (value < 0)
{
Console.WriteLine("エラー:年齢に0未満の値を設定することはできません");
}
else
{
age = value;
}
}
}
}このコードでは、名前、年齢を直接指定してインスタンスを生成できるようにするため、コンストラクタという特殊なメソッドを追加しています(コードの(a))。
名前、年齢のフィールドに対して適切な読み書きを行えるよう、プロパティという仕組みを使っています(コードの(b1)、(b2))。
それぞれ詳しく見ていきましょう。
ポイント1:コンストラクタ
インスタンスを生成するとき(new演算子で生成したとき)に呼び出される特殊なメソッドをコンストラクタといいます。
コンストラクタは、クラスと同名のメソッドとして定義します。戻り値はありません。
コンストラクタには引数を指定することも可能です。また、引数の異なるコンストラクタを複数定義することもできます。
コードの(a)をみてみましょう。
//★(a) コンストラクタ
public Person(string? name, int age)
{
this.name = name;
this.age = age;
}初期値となる名前、年齢を引数として指定できるコンストラクタを定義しています。
このコンストラクタでは、引数の変数名であるname,ageと、フィールド名のname、ageが被ってしまっていますね。
メソッド内で変数名を書くと、ローカル変数(引数も含む)が優先されます。
単にnameと書くと、ローカル変数(引数)のnameを指すことになります。
フィールド名を参照したい場合は「this.name」というふうに、「this.フィールド名」と記述します。これで、フィールドとローカル変数を区別できます。
thisは現在のインスタンスの参照となっています。
詳しくは、こちらの記事も御覧ください。
このようにコンストラクタを定義しておけば、以下のようにコード中で名前、年齢の具体値を指定してPersonインスタンスを生成することも可能になります。
Person user = new Person("プロ太", 30);これで、コンソールからの入力を扱う別のクラスを作れば、そのクラスがコンソールから読み込んだ情報を元にPersonインスタンスを生成できます。
コンストラクタはインスタンス生成時に必ず呼び出されます。
コンストラクタを明示的に定義しない場合、引数なしのコンストラクタが自動的に定義されます。
コンストラクタについてはこちらの記事も参考にしてください。
ポイント2:プロパティ
例えば、今回、Personのnameフィールドは参照のみ可能にし、書き換えは不可とする必要がありますね。
これは、以下のようなメソッドを追加すれば実現できます。
public string GetName()
{
return name;
}同様に、ageフィールドについても、以下のようなメソッドを追加すれば良いでしょう。
public int GetAge(){ ... }
public SetAge(int age) { ... } // ageが0未満かどうかのチェックも行うこれで、外部からのアクセスコントロールは適切に行えます。
しかし、この部品を使う側からすると、名前、年齢などフィールドらしきものへアクセスする感覚なのに、毎回GetXXX()、SetXXX()など書くのはちょっと煩わしいですね。
クラスを設計しているとアクセサが必要になる場面は多く、フィールドの数だけGetXXX()、SetXXX()がずらっと並ぶのは煩わしいのです。
この煩わしさを解決するためにプロパティがあります。
プロパティはprivateなフィールドに対して以下を両立させる仕組みです。
- 適切なアクセスコントロールを行う
- 外部から簡易な記述でアクセス可能にする
プロパティの基本的な定義方法は以下のようになります。
アクセス修飾子 型名 プロパティ名
{
get { ... }
set { ... }
}getはgetアクセサ、setはsetアクセサと呼ばれる特殊なメソッドです。
getにおける戻り値がプロパティを参照したときの値となり、setでは「value」というキーワードを使うとプロパティへ代入された値が取得できます。
プロパティへは、あたかもフィールドへアクセスするかのように参照や代入を行うことが可能です。
Personクラスの名前、年齢にアクセスするためのプロパティ定義をみてみましょう。
名前は読み取りのみ可能にするため、getアクセサのみ定義しています。
//★(b1) プロパティ (読み取りのみ)
public string? Name
{
get { return name; }
}これで、Personインスタンスの名前を以下のように参照できます。
そして、外部からの書き込みは行えません。
Person user = new Person("プロ太", 30);
Console.WriteLine(user.Name); //「プロ太」と表示される
user.Name = "プロ子"; //これはコンパイルエラーになる外部からのアクセスコントロールが、適切に行えていますね。
年齢は読み取りに加えて書き込みも行いたいので、getとsetの両方を定義しています。
年齢の値が設定されるときには、0未満であればエラーを表示し、値の更新を行いません。
//★(b2) プロパティ (読み取り/書き込み両方)
public int Age
{
get { return age; }
set {
if (value < 0)
{
Console.WriteLine("エラー:年齢に0未満の値を設定することはできません");
}
else
{
age = value;
}
}
}これで、以下のように年齢の読み書きができます。
Person user = new Person("プロ太", 30);
Console.WriteLine(user.Age); //30と表示される
user.Age = 31; //ageを31に更新する
user.Age = -1; //「エラー:…」と表示され、ageは更新されないPersonクラスの利用者は、user.Nameやuser.Ageといった感じで、フィールド参照する感覚で簡潔にアクセス可能です。
そして、アクセスコントロールや、内部でのチェックなどはきちんと行われます。
これで、HTMLコードで人の情報を出力するクラスを作成しようとしたときに、そのクラスが人の名前、年齢へ安全にアクセスすることが可能になりますね。
プロパティについてはこちらの記事も参考にしてください。
講義1:誰のために部品をブラックボックス化するのか?
ここまでの説明を聞いて、こう思った人もいるのではないでしょうか。
- ブラックボックス化して必要な機能だけ公開と言っているが、それはその部品を他人に使ってもらうときの話ではないのか?
- 他人に使ってもらう部品を作るとしても、その部品の内部を構成している自分だけが使う小さな部品群についてもブラックボックス化する必要があるのか?
仮に自分だけしか使わない部品を作るにしても、それをブラックボックス化しておくことは重要なのです。
自分の書いたコードといえどもコードの量が増えてくると、すべてのコードを把握し続けるのは困難になるためです。
そのため、その部品の詳細な中身を忘れてしまっても使えるようにすることが大事なのです。
以下の図を見てください。部品Aは適切にブラックボックス化された部品B、Cで構成されています。そして、同様に部品Bは部品D、E、部品Cは部品F、G、Hで構成されているとしましょう。
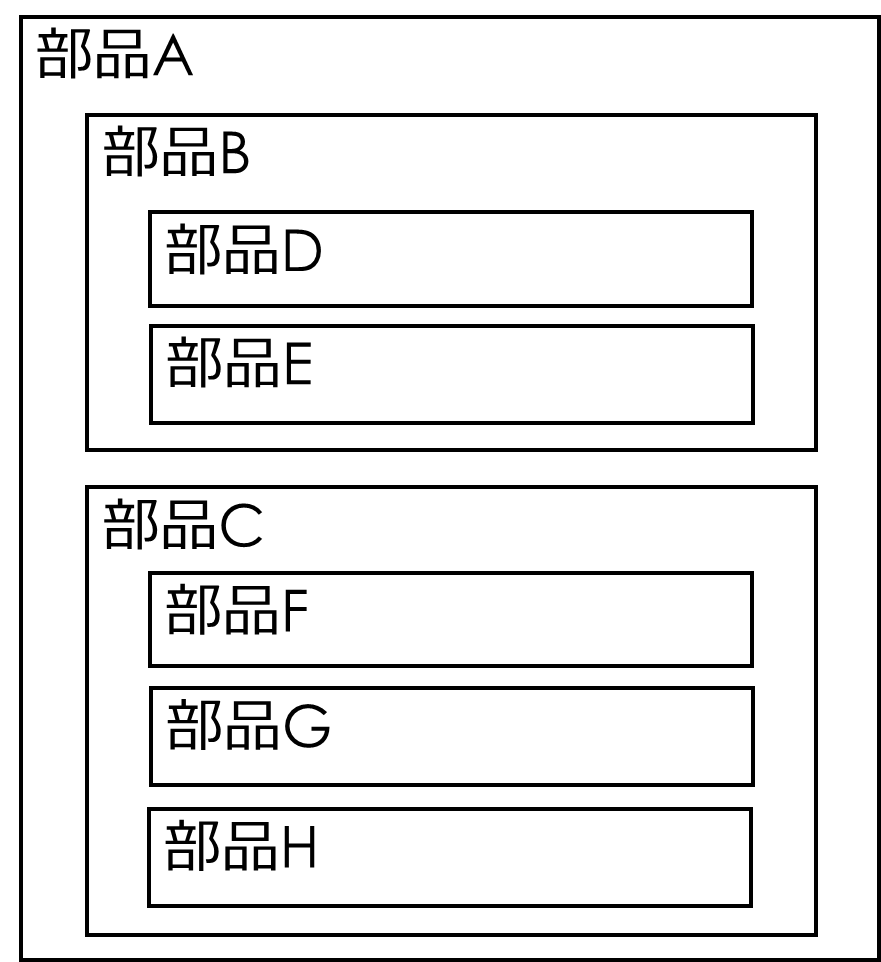
このとき、部品Aの中身を理解するためには、部品B、Cの外部公開された機能のみ理解すれば良いですね。
もし、部品Bの中身が知りたくなったら、今度は部品D、Eの外部公開された機能のみ理解すればよいわけです。
プログラムをトップダウンに理解していけるため、可読性の高いコードになっていますね。
チームで開発しているならば、自分の書いたコードを他の人が引き継いでメンテナンスしていくこともあるでしょう。
自分の書いたコードは1週間たったら他人の書いたコードなんていう話もありますね。
(人は忘れやすい生き物なのです…)
講義2:Visual Studioの自動補完
Visual StudioでC#プログラミングを行うと、コーディングの強力な支援を受けることができます。
特に、コードを途中まで書くと、残りを補完してくれる「自動補完」はとても便利な機能です。
例えば、以下のようにPerson型の変数userを宣言し、その後に「user.」まで入力します。
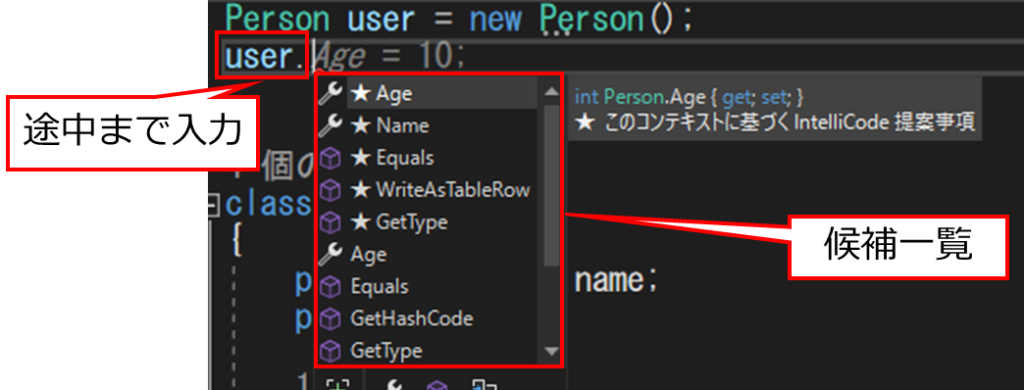
Personインスタンスのインスタンスメンバの一覧がでてきて、その中から必要なものを選ぶことができます。
もちろん、以下のようにクラスメンバについての自動補完もできます。
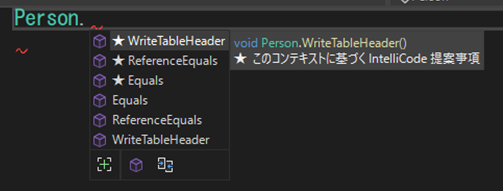
メソッド、プロパティ等の名前の一覧を見ると、そのクラスにはおおよそどのような機能が備わっているかを推測できます。
まとめ
今回は、オブジェクト指向の基本的な考え方と、カプセル化について説明しました。
オブジェクト指向では、データとそれに対する操作をひとまとまりにして部品化します。
カプセル化により外部へ公開する機能を限定し、詳細はブラックボックス化(隠蔽)することで、部品の再利用性を高めています。
これで、オブジェクト指向の考え方に沿って、クラス、フィールド、メソッド、プロパティなどを用いてコードを書けるようになりました。
次回は、オブジェクト指向における「継承」について解説します。





